Article Structure
Abstract
We consider the language identification problem for search engine queries.
Introduction
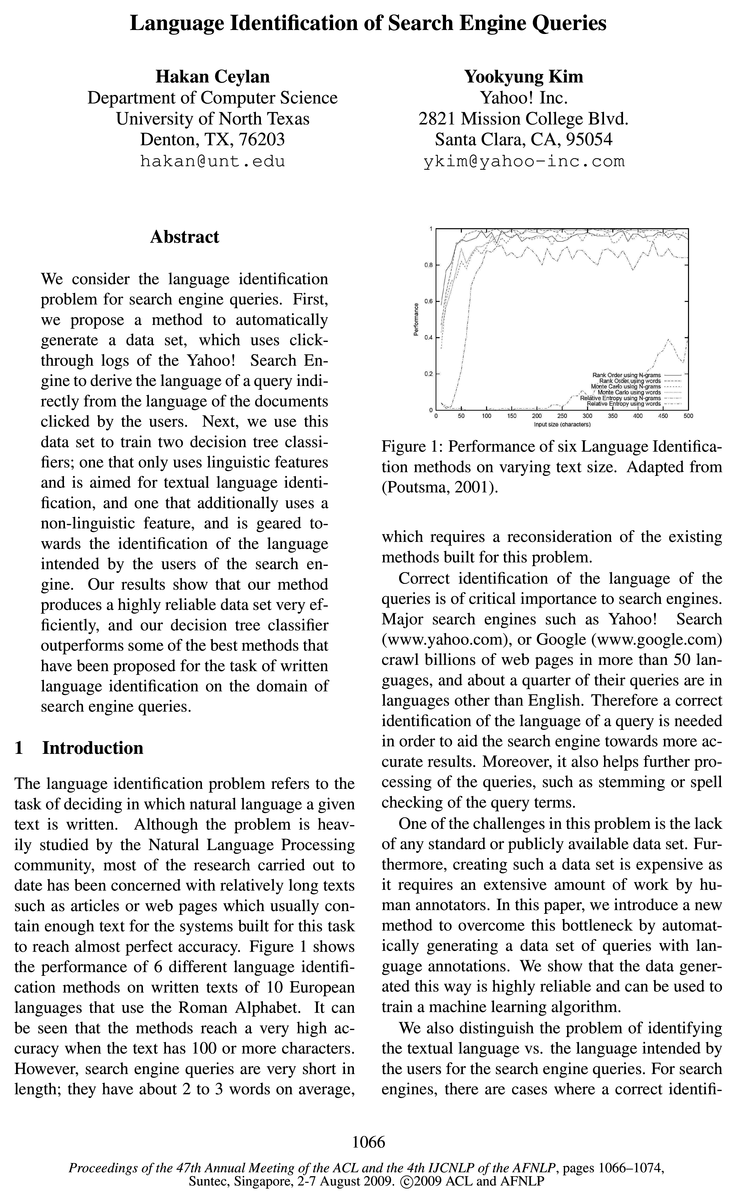
The language identification problem refers to the task of deciding in which natural language a given text is written.
Related Work
Most of the work carried out to date on the written language identification problem consists of supervised approaches that are trained on a list of words or n-gram models for each reference language.
Data Generation
We start the construction of our data set by retrieving the queries, together with the clicked urls, from the Yahoo!
Language Identification
We start this section with the implementation of three models each of which use a different existing feature.
Conclusions and Future Work
In this paper, we considered the language identification problem for search engine queries.
Acknowledgments
We are grateful to Romain Vinot, and Rada Mi-halcea, for their comments on an earlier draft of this paper.
Topics
n-gram
- Most of the work carried out to date on the written language identification problem consists of supervised approaches that are trained on a list of words or n-gram models for each reference language.Page 2, “Related Work”
- The n-gram based approaches are based on the counts of character or byte n-grams, which are sequences of n characters or bytes, extracted from a corpus for each reference language.Page 2, “Related Work”
- classification models that use the n-gram features have been proposed.Page 2, “Related Work”
- (Cavnar and Trenkle, 1994) used an out-of-place rank order statistic to measure the distance of a given text to the n-gram profile of each language.Page 2, “Related Work”
- (Sibun and Reynar, 1996) used Relative Entropy by first generating n-gram probability distributions for both training and test data, and then measuring the distance between the two probability distributions by using the Kullback-Liebler Distance.Page 2, “Related Work”
- Linguini, a system proposed by (Prager, 1999), combines the word-based and n-gram models using a vector-space based model and examines the effectiveness of the combined model and the individual features on varying text size.Page 2, “Related Work”
- We implement a statistical model using a character based n-gram feature.Page 5, “Language Identification”
- For each language, we collect the n-gram counts (for n = l to n = 7 also using the word beginning and ending spaces) from the vocabulary of the training corpus, and then generate a probability distribution from these counts.Page 5, “Language Identification”
- In other words, this time we used a word-based n-gram method, only with n = 1.Page 5, “Language Identification”
- The character based n-gram model outperforms all the other models with the exception of French, Spanish, and Italian on which the word-based unigram model is better.Page 5, “Language Identification”
- The Rank-Order method performs poorly compared to the character based n-gram model, which suggests that for shorter texts, a well-defined probability distribution with a proper discounting strategy is better than using an ad-hoc ranking method.Page 6, “Language Identification”
See all papers in Proc. ACL 2009 that mention n-gram.
See all papers in Proc. ACL that mention n-gram.
Back to top.
confidence score
- As the features of our DT classifier, we use the results of the models that are implemented in Section 4.1, together with the confidence scores calculated for each instance.Page 6, “Language Identification”
- To calculate a confidence score for the models, we note that since each model makes its selection based on the language that gives the highest probability, a confidence score should indicate the relative highness of that probability compared to the probabilities of other languages.Page 6, “Language Identification”
- where ,u’ and 0’ are the mean and the standard deviation values respectively, for a set of confidence scores calculated for a model on a small development set of 25 annotated queries from each language.Page 6, “Language Identification”
- Hence, for a given query, we calculate the identification result of each model together with the model’s confidence score, and then discretize the confidence score into one of the three categories described above.Page 7, “Language Identification”
- Next, we built a decision tree classifier that improves the results on average by combining the outputs of the three models together with their confidence scores .Page 8, “Conclusions and Future Work”
- Finally, we will consider other alternatives to the decision tree framework when combining the results of the models with their confidence scores .Page 8, “Conclusions and Future Work”
See all papers in Proc. ACL 2009 that mention confidence score.
See all papers in Proc. ACL that mention confidence score.
Back to top.
probability distribution
- (Sibun and Reynar, 1996) used Relative Entropy by first generating n-gram probability distributions for both training and test data, and then measuring the distance between the two probability distributions by using the Kullback-Liebler Distance.Page 2, “Related Work”
- For each language, we collect the n-gram counts (for n = l to n = 7 also using the word beginning and ending spaces) from the vocabulary of the training corpus, and then generate a probability distribution from these counts.Page 5, “Language Identification”
- From these counts, we obtained a probability distribution for all the words in our vocabulary.Page 5, “Language Identification”
- In Table 3, we present the top 10 results of the probability distributions obtained from the vocabulary of English, Finnish, and German corpora.Page 5, “Language Identification”
- The Rank-Order method performs poorly compared to the character based n-gram model, which suggests that for shorter texts, a well-defined probability distribution with a proper discounting strategy is better than using an ad-hoc ranking method.Page 6, “Language Identification”
- The success of the morphological feature depends heavily on the probability distribution of affixes in each language, which in turn depends on the corpus due to the unsupervised affix extraction algorithm.Page 6, “Language Identification”
See all papers in Proc. ACL 2009 that mention probability distribution.
See all papers in Proc. ACL that mention probability distribution.
Back to top.
Human annotations
- Furthermore, creating such a data set is expensive as it requires an extensive amount of work by human annotators .Page 1, “Introduction”
- We tested all the systems in this section on a test set of 3500 human annotated queries, which is formed by taking 350 Category-1 queries from each language.Page 5, “Language Identification”
- This query is labelled as Category-2 by the human annotator .Page 7, “Language Identification”
- Human annotations on 5000 automatically annotated queries showed that our data generation method is highly accurate, achieving 84.3% accuracy on average for Category-l queries, and 93.7% accuracy for Category-l and Category-2 queries combined.Page 8, “Conclusions and Future Work”
See all papers in Proc. ACL 2009 that mention Human annotations.
See all papers in Proc. ACL that mention Human annotations.
Back to top.
machine learning
- We show that the data generated this way is highly reliable and can be used to train a machine learning algorithm.Page 1, “Introduction”
- We then combine all three models in a machine learning framework using a novel approach.Page 5, “Language Identification”
- This way, we built a robust machine learning framework at a very low cost and without any human labour.Page 6, “Language Identification”
- We used the Weka Machine Learning Toolkit (Witten and Frank, 2005) to implement our DT classifier.Page 7, “Language Identification”
See all papers in Proc. ACL 2009 that mention machine learning.
See all papers in Proc. ACL that mention machine learning.
Back to top.
n-grams
- Rank OIflGR using words —-- ——onte‘Carfo usin - rams --» ---d/x 7,‘ Monte Carlo using words w ~ 7 ~ ’ Relative Entropy using N-grams — —~—-’ IRelative EIntropy usin words If r r wPage 1, “Introduction”
- The n-gram based approaches are based on the counts of character or byte n-grams , which are sequences of n characters or bytes, extracted from a corpus for each reference language.Page 2, “Related Work”
- (Dunning, 1994) proposed a system that uses Markov Chains of byte n-grams with Bayesian Decision Rules to minimize the probability error.Page 2, “Related Work”
See all papers in Proc. ACL 2009 that mention n-grams.
See all papers in Proc. ACL that mention n-grams.
Back to top.
Natural Language
- The language identification problem refers to the task of deciding in which natural language a given text is written.Page 1, “Introduction”
- Although the problem is heavily studied by the Natural Language Processing community, most of the research carried out to date has been concerned with relatively long texts such as articles or web pages which usually contain enough text for the systems built for this task to reach almost perfect accuracy.Page 1, “Introduction”
- Through an investigation of Category-2 non-English queries, we find out that this is mostly due to the usage of some common internet or computer terms such as ”download”, ”software”, ”flash player”, among other native language query terms.Page 5, “Data Generation”
See all papers in Proc. ACL 2009 that mention Natural Language.
See all papers in Proc. ACL that mention Natural Language.
Back to top.