Article Structure
Abstract
We present a simple yet powerful hierarchical search algorithm for automatic word alignment.
Introduction
Automatic word alignment is generally accepted as a first step in training any statistical machine translation system.
Word Alignment as a Hypergraph
Algorithm input The input to our alignment algorithm is a sentence-pair (e’i‘, 1m) and a parse tree over one of the input sentences.
Discriminative training
We incorporate all our new features into a linear model and learn weights for each using the online averaged perceptron algorithm (Collins, 2002) with a few modifications for structured outputs inspired by Chiang et al.
Features
Our simple, flexible linear model makes it easy to throw in many features, mapping a given complex
Related Work
Recent work has shown the potential for syntactic information encoded in various ways to support inference of superior word alignments.
Experiments
We evaluate our model and and resulting alignments on Arabic-English data against those induced by IBM Model-4 using GIZA++ (Och and Ney, 2003) with both the union and grow-diag-final heuristics.
Conclusion
We have opened up the word alignment task to advances in hypergraph algorithms currently used in parsing and machine translation decoding.
Topics
word alignment
- We present a simple yet powerful hierarchical search algorithm for automatic word alignment .Page 1, “Abstract”
- We report results on Arabic-English word alignment and translation tasks.Page 1, “Abstract”
- Automatic word alignment is generally accepted as a first step in training any statistical machine translation system.Page 1, “Introduction”
- has motivated much recent work in discriminative modeling for word alignment (Moore, 2005; Itty-cheriah and Roukos, 2005; Liu et al., 2005; Taskar et al., 2005; Blunsom and Cohn, 2006; Lacoste-Julien et al., 2006; Moore et al., 2006).Page 1, “Introduction”
- We borrow ideas from both k—best parsing (Klein and Manning, 2001; Huang and Chiang, 2005; Huang, 2008) and forest-based, and hierarchical phrase-based translation (Huang and Chiang, 2007; Chiang, 2007), and apply them to word alignment .Page 1, “Introduction”
- word alignments , from which we can efficiently extract the k-best.Page 2, “Introduction”
- Finally, we use relatively little training data to achieve accurate word alignments .Page 2, “Introduction”
- Word alignments are built bottom-up on the parse tree.Page 2, “Word Alignment as a Hypergraph”
- Initial partial alignments are enumerated and scored at preterminal nodes, each spanning a single column of the word alignment matrix.Page 3, “Word Alignment as a Hypergraph”
- Initial alignments We can construct a word alignment hierarchically, bottom-up, by making use of the structure inherent in syntactic parse trees.Page 3, “Word Alignment as a Hypergraph”
- We can think of building a word alignment as filling in an M ><N matrix (Figure l), and we begin by visiting each preterminal node in the tree.Page 3, “Word Alignment as a Hypergraph”
See all papers in Proc. ACL 2010 that mention word alignment.
See all papers in Proc. ACL that mention word alignment.
Back to top.
parse tree
- Using a foreign string and an English parse tree as input, we formulate a bottom-up search on the parse tree , with the structure of the tree as a backbone for building a hypergraph of possible alignments.Page 1, “Introduction”
- Algorithm input The input to our alignment algorithm is a sentence-pair (e’i‘, 1m) and a parse tree over one of the input sentences.Page 2, “Word Alignment as a Hypergraph”
- To generate parse trees , we use the Berkeley parser (Petrov et al., 2006), and use Collins head rules (Collins, 2003) to head-out binarize each tree.Page 2, “Word Alignment as a Hypergraph”
- Word alignments are built bottom-up on the parse tree .Page 2, “Word Alignment as a Hypergraph”
- (1) that using the structure of l-best English syntactic parse trees is a reasonable way to frame and drive our search, and (2) that F-measure approximately decomposes over hyperedges.Page 3, “Word Alignment as a Hypergraph”
- Initial alignments We can construct a word alignment hierarchically, bottom-up, by making use of the structure inherent in syntactic parse trees .Page 3, “Word Alignment as a Hypergraph”
- Algorithm 1: Hypergraph Alignment Input: Source sentence e’f Target sentence fl’” Parse tree T over e’f Set of feature functions h Weight vector w Beam size k Output:Page 4, “Word Alignment as a Hypergraph”
- Feature development Our features are inspired by analysis of patterns contained among our gold alignment data and automatically generated parse trees .Page 5, “Features”
- link (e, f) if the part-of-speech tag of e is t. The conditional probabilities in this table are computed from our parse trees and the baseline Model 4 alignments.Page 6, “Features”
- 0 Features PP-NP-head, NP-DT-head, and VP-VP-head (Figure 6) all exploit headwords on the parse tree .Page 7, “Features”
See all papers in Proc. ACL 2010 that mention parse tree.
See all papers in Proc. ACL that mention parse tree.
Back to top.
F-measure
- Our model outperforms a GIZA++ Model-4 baseline by 6.3 points in F-measure , yielding a 1.1 BLEU score increase over a state-of-the-art syntax-based machine translation system.Page 1, “Abstract”
- (1) that using the structure of l-best English syntactic parse trees is a reasonable way to frame and drive our search, and (2) that F-measure approximately decomposes over hyperedges.Page 3, “Word Alignment as a Hypergraph”
- Note that Equation 2 is equivalent to maximizing the sum of the F-measure and model score of y:Page 5, “Discriminative training”
- These plots show the current F-measure on the training set as time passes.Page 8, “Experiments”
- F-measurePage 8, “Experiments”
- The first three columns of Table 2 show the balanced F-measure , Precision, and Recall of our alignments versus the two GIZA++ Model-4 baselines.Page 8, “Experiments”
- We report an F-measure 8.6 points over Model-4 union, and 6.3 points over Model-4 grow-diag-final.Page 8, “Experiments”
- We treat word alignment as a parsing problem, and by taking advantage of English syntax and the hypergraph structure of our search algorithm, we report significant increases in both F-measure and BLEU score over standard baselines in use by most state-of-the-art MT systems today.Page 9, “Conclusion”
See all papers in Proc. ACL 2010 that mention F-measure.
See all papers in Proc. ACL that mention F-measure.
Back to top.
BLEU
- Our model outperforms a GIZA++ Model-4 baseline by 6.3 points in F-measure, yielding a 1.1 BLEU score increase over a state-of-the-art syntax-based machine translation system.Page 1, “Abstract”
- Very recent work in word alignment has also started to report downstream effects on BLEU score.Page 8, “Related Work”
- (2009) confirm and extend these results, showing BLEU improvement for a hierarchical phrase-based MT system on a small Chinese corpus.Page 8, “Related Work”
- BLEU Words .696 45.1 2,538 .674 46.4 2,262Page 9, “Experiments”
- Our hypergraph alignment algorithm allows us a 1.1 BLEU increase over the best baseline system, Model-4 grow-diag-final.Page 9, “Experiments”
- We also report a 2.4 BLEU increase over a system trained with alignments from Model-4 union.Page 9, “Experiments”
- We treat word alignment as a parsing problem, and by taking advantage of English syntax and the hypergraph structure of our search algorithm, we report significant increases in both F-measure and BLEU score over standard baselines in use by most state-of-the-art MT systems today.Page 9, “Conclusion”
See all papers in Proc. ACL 2010 that mention BLEU.
See all papers in Proc. ACL that mention BLEU.
Back to top.
perceptron
- We train the parameters of the model using averaged perceptron (Collins, 2002) modified for structured outputs, but can easily fit into a max-margin or related framework.Page 2, “Introduction”
- We incorporate all our new features into a linear model and learn weights for each using the online averaged perceptron algorithm (Collins, 2002) with a few modifications for structured outputs inspired by Chiang et al.Page 4, “Discriminative training”
- We use 1,000 sentence pairs and gold alignments from LDC2006E86 to train model parameters: 800 sentences for training, 100 for testing, and 100 as a second held-out development set to decide when to stop perceptron training.Page 8, “Experiments”
- Figure 8: Learning curves for 10 random restarts over time for parallel averaged perceptron training.Page 8, “Experiments”
- Perceptron training here is quite stable, converging to the same general neighborhood each time.Page 8, “Experiments”
- Figure 8 shows the stability of the search procedure over ten random restarts of parallel averaged perceptron training with 40 CPUs.Page 9, “Experiments”
See all papers in Proc. ACL 2010 that mention perceptron.
See all papers in Proc. ACL that mention perceptron.
Back to top.
translation system
- Our model outperforms a GIZA++ Model-4 baseline by 6.3 points in F-measure, yielding a 1.1 BLEU score increase over a state-of-the-art syntax-based machine translation system .Page 1, “Abstract”
- Automatic word alignment is generally accepted as a first step in training any statistical machine translation system .Page 1, “Introduction”
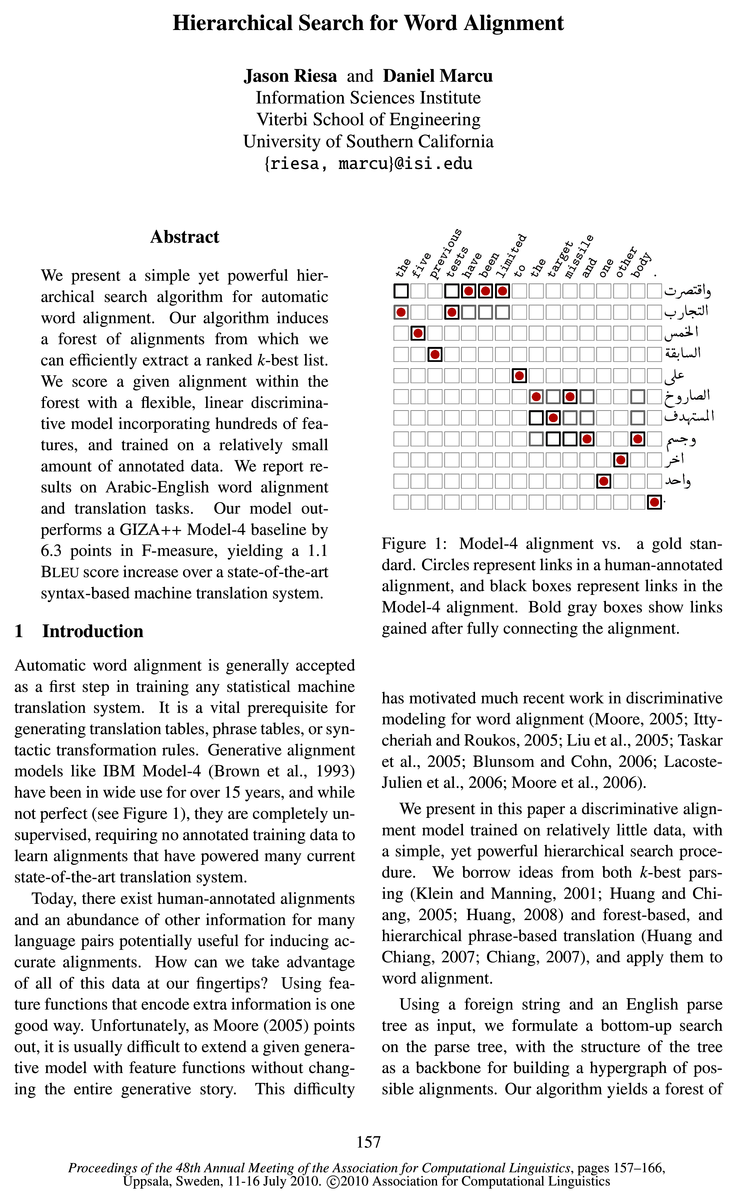
- Generative alignment models like IBM Model-4 (Brown et al., 1993) have been in wide use for over 15 years, and while not perfect (see Figure 1), they are completely unsupervised, requiring no annotated training data to learn alignments that have powered many current state-of-the-art translation system .Page 1, “Introduction”
- For each set of translation rules, we train a machine translation system and decode a held-out test corpus for which we report results below.Page 9, “Experiments”
- We use a syntax-based translation system for these experiments.Page 9, “Experiments”
See all papers in Proc. ACL 2010 that mention translation system.
See all papers in Proc. ACL that mention translation system.
Back to top.
machine translation
- Our model outperforms a GIZA++ Model-4 baseline by 6.3 points in F-measure, yielding a 1.1 BLEU score increase over a state-of-the-art syntax-based machine translation system.Page 1, “Abstract”
- Automatic word alignment is generally accepted as a first step in training any statistical machine translation system.Page 1, “Introduction”
- For each set of translation rules, we train a machine translation system and decode a held-out test corpus for which we report results below.Page 9, “Experiments”
- We have opened up the word alignment task to advances in hypergraph algorithms currently used in parsing and machine translation decoding.Page 9, “Conclusion”
See all papers in Proc. ACL 2010 that mention machine translation.
See all papers in Proc. ACL that mention machine translation.
Back to top.
part-of-speech
- We employ a separate instance of this feature for each English part-of-speech tag: p( f | e, t).Page 5, “Features”
- link (e, f) if the part-of-speech tag of e is t. The conditional probabilities in this table are computed from our parse trees and the baseline Model 4 alignments.Page 6, “Features”
- These fire for for each link (e, f) and part-of-speech tag.Page 6, “Features”
- That is, we learn a separate weight for each feature for each part-of-speech tag in our data.Page 6, “Features”
See all papers in Proc. ACL 2010 that mention part-of-speech.
See all papers in Proc. ACL that mention part-of-speech.
Back to top.
part-of-speech tag
- We employ a separate instance of this feature for each English part-of-speech tag : p( f | e, t).Page 5, “Features”
- link (e, f) if the part-of-speech tag of e is t. The conditional probabilities in this table are computed from our parse trees and the baseline Model 4 alignments.Page 6, “Features”
- These fire for for each link (e, f) and part-of-speech tag .Page 6, “Features”
- That is, we learn a separate weight for each feature for each part-of-speech tag in our data.Page 6, “Features”
See all papers in Proc. ACL 2010 that mention part-of-speech tag.
See all papers in Proc. ACL that mention part-of-speech tag.
Back to top.
alignment model
- Generative alignment models like IBM Model-4 (Brown et al., 1993) have been in wide use for over 15 years, and while not perfect (see Figure 1), they are completely unsupervised, requiring no annotated training data to learn alignments that have powered many current state-of-the-art translation system.Page 1, “Introduction”
- We present in this paper a discriminative alignment model trained on relatively little data, with a simple, yet powerful hierarchical search procedure.Page 1, “Introduction”
- We align the same core subset with our trained hypergraph alignment model , and extract a second set of translation rules.Page 9, “Experiments”
See all papers in Proc. ACL 2010 that mention alignment model.
See all papers in Proc. ACL that mention alignment model.
Back to top.
BLEU score
- Our model outperforms a GIZA++ Model-4 baseline by 6.3 points in F-measure, yielding a 1.1 BLEU score increase over a state-of-the-art syntax-based machine translation system.Page 1, “Abstract”
- Very recent work in word alignment has also started to report downstream effects on BLEU score .Page 8, “Related Work”
- We treat word alignment as a parsing problem, and by taking advantage of English syntax and the hypergraph structure of our search algorithm, we report significant increases in both F-measure and BLEU score over standard baselines in use by most state-of-the-art MT systems today.Page 9, “Conclusion”
See all papers in Proc. ACL 2010 that mention BLEU score.
See all papers in Proc. ACL that mention BLEU score.
Back to top.
MT system
- (2009) confirm and extend these results, showing BLEU improvement for a hierarchical phrase-based MT system on a small Chinese corpus.Page 8, “Related Work”
- We tune the the parameters of the MT system on a held-out development corpus of 1,172 parallel sentences, and test on a held-out parallel corpus of 746 parallel sentences.Page 9, “Experiments”
- We treat word alignment as a parsing problem, and by taking advantage of English syntax and the hypergraph structure of our search algorithm, we report significant increases in both F-measure and BLEU score over standard baselines in use by most state-of-the-art MT systems today.Page 9, “Conclusion”
See all papers in Proc. ACL 2010 that mention MT system.
See all papers in Proc. ACL that mention MT system.
Back to top.
syntactic parse
- In this work, we parse our English data, and for each sentence E = e’f, let T be its syntactic parse .Page 2, “Word Alignment as a Hypergraph”
- (1) that using the structure of l-best English syntactic parse trees is a reasonable way to frame and drive our search, and (2) that F-measure approximately decomposes over hyperedges.Page 3, “Word Alignment as a Hypergraph”
- Initial alignments We can construct a word alignment hierarchically, bottom-up, by making use of the structure inherent in syntactic parse trees.Page 3, “Word Alignment as a Hypergraph”
See all papers in Proc. ACL 2010 that mention syntactic parse.
See all papers in Proc. ACL that mention syntactic parse.
Back to top.