Article Structure
Abstract
We derive variants of the fertility based models IBM-3 and IBM-4 that, while maintaining their zero and first order parameters, are nondeficient.
Introduction
While most people think of the translation and word alignment models IBM-3 and IBM-4 as inherently deficient models (i.e.
The models IBM-3, IBM-4 and IBM-5
We begin with a short review of fertility-based models in general and IBM-3, IBM-4 and IBM-5 specifically.
Nondeficient Variants of IBM-3 and IBM-4
From now on we always enforce that for each position i the indices d”, are generated in ascending order (dz-,1c > di,k_1 for k > 1).
Training the New Variants
For the task of word alignment, we infer the parameters of the models using the maximum likeli-
See e. g. the author’s course notes (in German), currently
http://user.phil—fak.uni—duesseldorf.de/ ~tosch/olownloaols/statmt/worolalign.polf.
Conclusion
We have shown that the word alignment models IBM-3 and IBM-4 can be turned into nondeficient
Topics
word alignment
- While most people think of the translation and word alignment models IBM-3 and IBM-4 as inherently deficient models (i.e.Page 1, “Introduction”
- The source code of this project is available in our word alignment software RegAlignerl, version 1.2 and later.Page 2, “Introduction”
- Related Work Today’s most widely used models for word alignment are still the models IBM 1-5 of Brown et al.Page 2, “Introduction”
- While it is known that fertility-based models outperform sequence-based ones, the large bulk of word alignment literature following these publications has mostly ignored fertility-based models.Page 2, “Introduction”
- The number is not entirely fair as alignments where more than half the words align to the empty word are assigned a probability of 0.Page 2, “Introduction”
- bility p(fi] |e{) of getting the foreign sentence as a translation of the English one is modeled by introducing the word alignment a as a hidden variable:Page 2, “The models IBM-3, IBM-4 and IBM-5”
- ,I, decide on the number (I),-of foreign words aligned to 6,.Page 3, “The models IBM-3, IBM-4 and IBM-5”
- Foreachi=l,2,...,I, andk = l,...,<l>z-decide on (a) the identity fiyc of the next foreign word aligned to 6,.Page 3, “The models IBM-3, IBM-4 and IBM-5”
- For the task of word alignment , we infer the parameters of the models using the maximum likeli-Page 5, “Training the New Variants”
- This task is also needed for the actual task of word alignment (annotating a given sentence pair with an alignment).Page 5, “Training the New Variants”
- We have shown that the word alignment models IBM-3 and IBM-4 can be turned into nondeficientPage 9, “Conclusion”
See all papers in Proc. ACL 2013 that mention word alignment.
See all papers in Proc. ACL that mention word alignment.
Back to top.
Viterbi
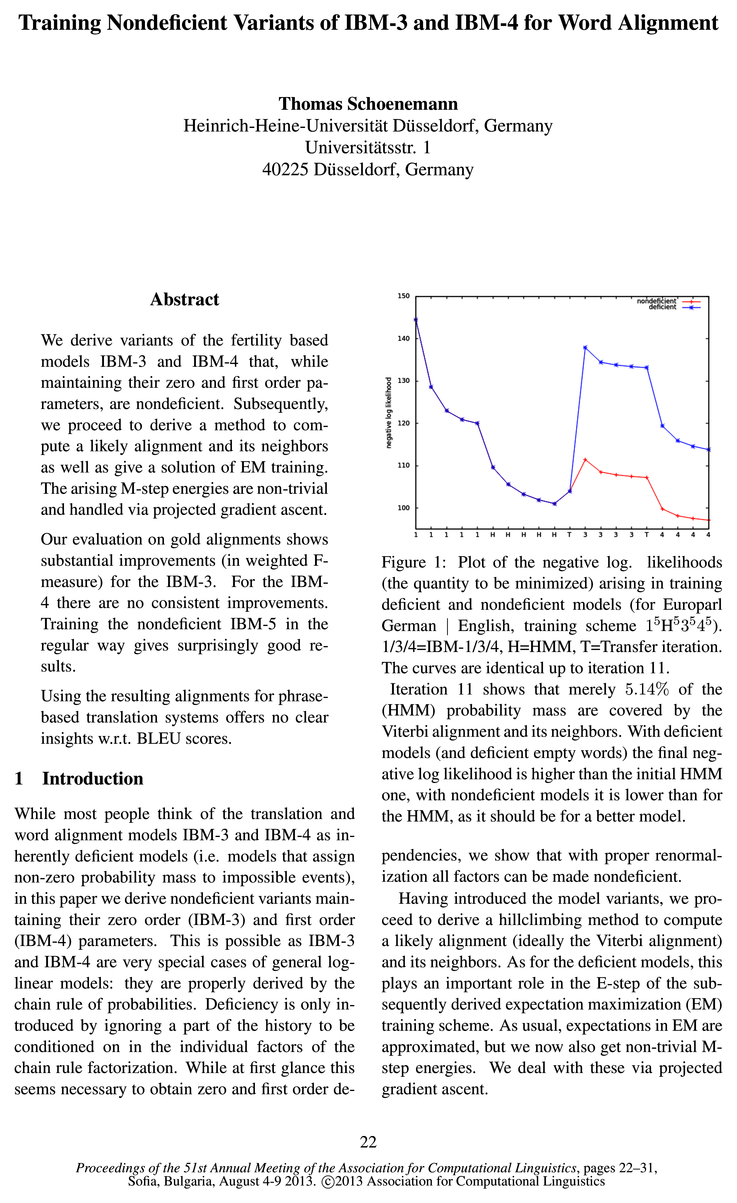
- Iteration 11 shows that merely 5.14% of the (HMM) probability mass are covered by the Viterbi alignment and its neighbors.Page 1, “Introduction”
- Having introduced the model variants, we proceed to derive a hillclimbing method to compute a likely alignment (ideally the Viterbi alignment) and its neighbors.Page 1, “Introduction”
- As an aside, the transfer iteration from HMM to IBM3 (iteration 11) reveals that only 5.14% of the probability mass3 are preserved when using the Viterbi alignment and its neighbors instead of all alignments.Page 2, “Introduction”
- One reason for the lack of interest is surely that computing expectations and Viterbi alignments for these models is a hard problem (Udupa and Maji, 2006).Page 2, “Introduction”
- Nevertheless, computing Viterbi align-Page 2, “Introduction”
- As in the training of the deficient IBM-3 and IBM-4 models, we approximate the expectations in the E-step by a set of likely alignments, ideally centered around the Viterbi alignment, but already for the regular deficient variants computing it is NP-hard (Udupa and Maji, 2006).Page 5, “Training the New Variants”
- In the E-step we use hillclimbing to get a likely alignment (ideally the Viterbi alignment).Page 9, “Conclusion”
See all papers in Proc. ACL 2013 that mention Viterbi.
See all papers in Proc. ACL that mention Viterbi.
Back to top.
sentence pairs
- The downside of our method is its resource consumption, but still we present results on corpora with 100.000 sentence pairs .Page 2, “Introduction”
- sentence pairs 3 = l, .Page 5, “Training the New Variants”
- This task is also needed for the actual task of word alignment (annotating a given sentence pair with an alignment).Page 5, “Training the New Variants”
- However, since we approximate expectations from the move and swap matrices, and hence by (9((1 + J) - J) alignments per sentence pair , in the end we get a polynomial number of terms.Page 7, “See e. g. the author’s course notes (in German), currently”
- We use MOSES with a 5-gram language model (trained on 500.000 sentence pairs ) and the standard setup in the MOSES Experiment Management System: training is run in both directions, the alignments are combined using diag—grow—final—and (Och and Ney, 2003) and the parameters of MOSES are optimized on 750 development sentences.Page 9, “See e. g. the author’s course notes (in German), currently”
- Table 2: Evaluation of phrase-based translation from German to English with the obtained alignments (for 100.000 sentence pairs ).Page 9, “Conclusion”
See all papers in Proc. ACL 2013 that mention sentence pairs.
See all papers in Proc. ACL that mention sentence pairs.
Back to top.
phrase-based
- Using the resulting alignments for phrase-based translation systems offers no clear insights w.r.t.Page 1, “Abstract”
- In addition we evaluate the effect on phrase-based translation on one of the tasks.Page 8, “See e. g. the author’s course notes (in German), currently”
- We also check the effect of the various alignments (all produced by RegAligner) on translation performance for phrase-based translation, randomly choosing translation from German to English.Page 9, “See e. g. the author’s course notes (in German), currently”
- Table 2: Evaluation of phrase-based translation from German to English with the obtained alignments (for 100.000 sentence pairs).Page 9, “Conclusion”
See all papers in Proc. ACL 2013 that mention phrase-based.
See all papers in Proc. ACL that mention phrase-based.
Back to top.
iteratively
- For computing alignments, we use the common procedure of hillclimbing where we start with an alignment, then iteratively compute the probabilities of all alignments differing by a move or a swap (Brown et al., 1993) and move to the best of these if it beats the current alignment.Page 5, “Training the New Variants”
- Proper EM The expectation maximization (EM) framework (Dempster et al., 1977; Neal and Hinton, 1998) is a class of template procedures (rather than a proper algorithm) that iteratively requires solving the taskPage 6, “Training the New Variants”
- for some (differentiable) function one iteratively starts at the current point {pkg computes the gradient VEi({pk(j and goes to the pointPage 7, “See e. g. the author’s course notes (in German), currently”
See all papers in Proc. ACL 2013 that mention iteratively.
See all papers in Proc. ACL that mention iteratively.
Back to top.
probabilistic modeling
- H221 k denotes the factorial of n. The main difference between IBM-3, IBM-4 and IBM-5 is the choice of probability model in step 3 b), called a distortion model.Page 3, “The models IBM-3, IBM-4 and IBM-5”
- In total, the IBM-3 has the following probability model:Page 3, “The models IBM-3, IBM-4 and IBM-5”
- variants, an important aim of probabilistic modeling for word alignment.Page 9, “Conclusion”
See all papers in Proc. ACL 2013 that mention probabilistic modeling.
See all papers in Proc. ACL that mention probabilistic modeling.
Back to top.