Article Structure
Abstract
Wikipedia infoboxes are a valuable source of structured knowledge for global knowledge sharing.
Introduction
In recent years, the automatic knowledge extraction using Wikipedia has attracted significant research interest in research fields, such as the semantic web.
Preliminaries
In this section, we introduce some basic concepts regarding Wikipedia, formally defining the key problem of cross-lingual knowledge extraction and providing an overview of the WikiCiKE framework.
Our Approach
In this section, we will present the detailed approaches used in WikiCiKE.
Experiments
In this section, we present our experiments to evaluate the effectiveness of WikiCiKE, where we focus on the Chinese-English case; in other words, the target language is Chinese and the source language is English.
Related Work
Some approaches of knowledge extraction from the open Web have been proposed (Wu et al., 2012; Yates et al., 2007).
Conclusion and Future Work
In this paper we proposed a general cross-lingual knowledge extraction framework called WikiCiKE, in which extraction performance in the target Wikipedia is improved by using rich infoboxes in the source language.
Topics
cross-lingual
- In this paper, we formulate the problem of cross-lingual knowledge extraction from multilingual Wikipedia sources, and present a novel framework, called WikiCiKE, to solve this problem.Page 1, “Abstract”
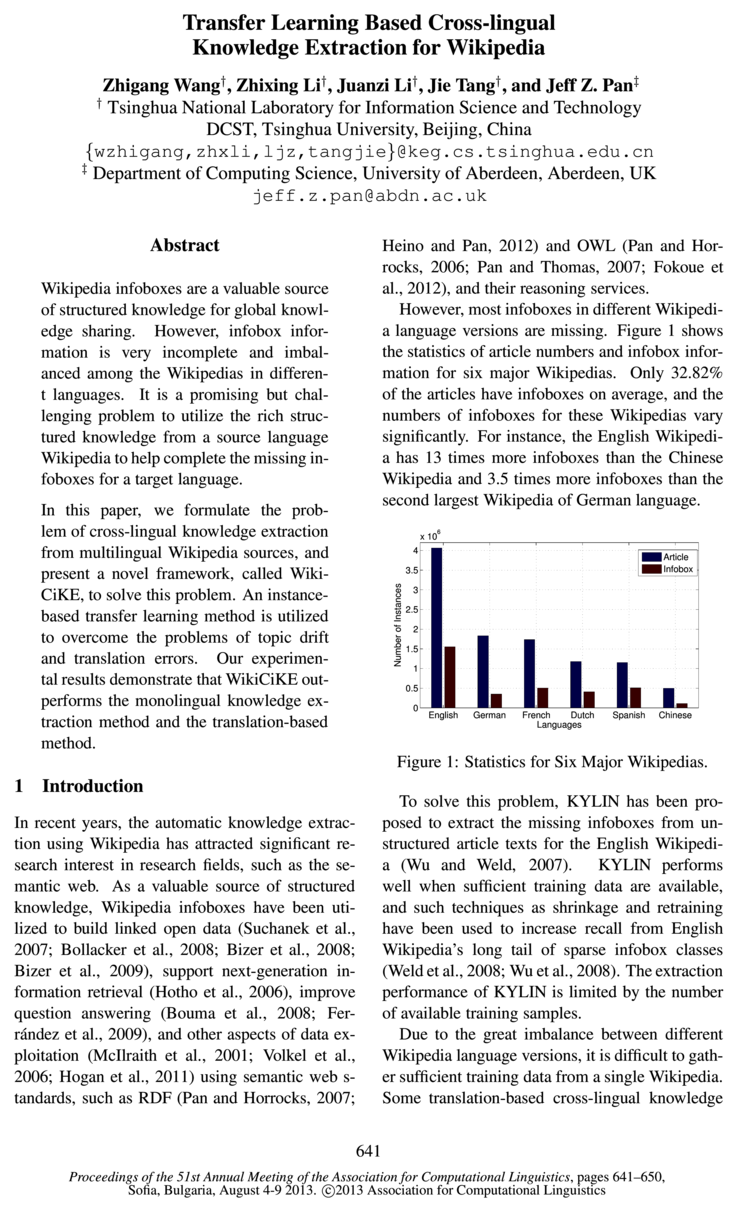
- Some translation-based cross-lingual knowledgePage 1, “Introduction”
- The recall of new target infoboxes is highly limited by the number of equivalent cross-lingual articles and the number of existing source infoboxes.Page 2, “Introduction”
- In general, we address the problem of cross-lingual knowledge extraction by using the imbalance between Wikipedias of different languages.Page 2, “Introduction”
- Specifically, we treat this cross-lingual information extraction task as a transfer learning-based binary classification problem.Page 2, “Introduction”
- We propose a transfer learning-based cross-lingual knowledge extraction frameworkPage 2, “Introduction”
- In this section, we introduce some basic concepts regarding Wikipedia, formally defining the key problem of cross-lingual knowledge extraction and providing an overview of the WikiCiKE framework.Page 2, “Preliminaries”
- We will use “name in TEMPLATE PERSON” to refer to the attribute attrname in the template tp p E R30 N. In this cross-lingual task, we use the source (S) and target (T) languages to denote the languages of auxiliary and target Wikipcdias, rc-spcctivcly.Page 3, “Preliminaries”
- To generate the training data for the target attribute attrT, we first determine the equivalent cross-lingual attribute attrs.Page 4, “Our Approach”
- Therefore, it is convenient to align the cross-lingual attributes using English Wikipedia as bridge.Page 4, “Our Approach”
- It obtains the values by two steps: finding their counterparts (if available) in English using Wikipedia cross-lingual links and attribute alignments, and translating them into Chinese.Page 6, “Experiments”
See all papers in Proc. ACL 2013 that mention cross-lingual.
See all papers in Proc. ACL that mention cross-lingual.
Back to top.
knowledge base
- 2.1 Wiki Knowledge Base and Wiki ArticlePage 2, “Preliminaries”
- We consider each language version of Wikipedia as a wiki knowledge base , which can be represented as K = {ai H21, where at, is a disambiguated article in K and p is the size of K.Page 2, “Preliminaries”
- For example, K 3 indicates the source wiki knowledge base, and KT denotes the target wiki knowledge base .Page 3, “Preliminaries”
- As shown in Figure 3, WikiCiKE contains four key components: (1) Automatic Training Data Generation: given the target attribute attrT and two wiki knowledge bases K 3 and KT, WikiCiKE first generates the training data set TD 2 TBS U TDT automatically.Page 3, “Preliminaries”
- In theory, WikiCiKE can be applied to any two wiki knowledge based of different languages.Page 9, “Conclusion and Future Work”
See all papers in Proc. ACL 2013 that mention knowledge base.
See all papers in Proc. ACL that mention knowledge base.
Back to top.
feature vector
- :10, can be represented as a feature vector according to its context.Page 3, “Preliminaries”
- Then, we use a uniform automatic method, which primarily consists of word labeling and feature vector generation, to generate the training data set TD 2 {(55, from these collected articles.Page 4, “Our Approach”
- (1) After the word labeling, each instance (word/token) is represented as a feature vector .Page 4, “Our Approach”
- First, we turn the team: into a word sequence and compute the feature vector for each word based on the feature definition in Section 3.1.Page 5, “Our Approach”
See all papers in Proc. ACL 2013 that mention feature vector.
See all papers in Proc. ACL that mention feature vector.
Back to top.
Chinese-English
- Chinese-English experiments for four typical attributes demonstrate that WikiCiKE outperforms both the monolingual extraction method and current translation-based method.Page 2, “Introduction”
- In this section, we present our experiments to evaluate the effectiveness of WikiCiKE, where we focus on the Chinese-English case; in other words, the target language is Chinese and the source language is English.Page 6, “Experiments”
- Chinese-English experimental results on four typical attributes showed that WikiCiKE significantly outperforms both the current translation based methods and the monolingual extraction methods.Page 9, “Conclusion and Future Work”
See all papers in Proc. ACL 2013 that mention Chinese-English.
See all papers in Proc. ACL that mention Chinese-English.
Back to top.
POS tag
- As shown in Table 2, we classify the features used in WikiCiKE into three categories: format features, POS tag features and token features.Page 4, “Our Approach”
- POS tag POS tag of current token features POS tags of previous 5 tokensPage 4, “Our Approach”
- POS tags ofPage 4, “Our Approach”
See all papers in Proc. ACL 2013 that mention POS tag.
See all papers in Proc. ACL that mention POS tag.
Back to top.
word segmentation
- The first category is caused by incorrect word segmentation (40.85%).Page 8, “Experiments”
- The result of word segmentation directly decide the performance of extraction so it causes most of the errors.Page 8, “Experiments”
- In the future, we can improve the performance of WikiCiKE by polishing the word segmentation result.Page 8, “Experiments”
See all papers in Proc. ACL 2013 that mention word segmentation.
See all papers in Proc. ACL that mention word segmentation.
Back to top.